Machines Which Imitate Human Learning
Machines can imitate human learning capability via construction of computer programs that automatically improve performance based on experience and self-discovery. This scientific discipline is called Machine learning (ML) which is a sub-branch of Artificial Intelligence (AI). ML is a diverse multi-disciplinary field you can ever imagine. It combines & uses ideas from traditional symbolic & rule-based AI, Soft-Computing, Probability, Statistics, Information Theory and Signal Processing, Computational Complexity, Computational Mathematics, Philosophy, Control Systems Theory, Cognitive Psychology, Biology, Economics, Linguistics, Operations Research (OR), Physics, and other areas that have been explored in the last decade.
Introduction
The idea of creating intelligent machines has attracted humans since ancient times. Today, with the huge development of computers and 50 years of research into AI programming techniques, the dream of intelligent machines is closer to becoming a reality. The successful application of machine learning (ML) recently involves data-mining programs that learn to monitor and detect international money laundering or fraudulent credit card transactions, information filtering systems that learn the users reading preferences; systems that automatically diagnose cancer risk by scanning patients MRI images to autonomous vehicles that learn to drive on their own on public highways in the presence of other vehicles such as Google self-drive cars & so forth. This field has long held potential for automating the time-consuming and expensive process of knowledge acquisition, but only in the past decade have techniques from machine learning started to play a significant role in industry. Machine learning has just been in widespread use in different industries within the last 15 years. This is the approximate length of time that the Internet has been widely adopted. The use of machine learning is now very big today & it is expected to grow exponentially over the coming years, and any company that is jumping on to this new revolutionary technology will produce software products that are very competitive in the market.
Learning
Humans learn by being taught, that is, by a teacher or by a parent or by an expert in a specific knowledge domain, etc; or they are self-taught or learn via self-discovery, as in the case of a researcher. A physics teacher at a high school teaches Newton’s Laws of Motion to his/her students. The students learn all these concepts of physics from the teacher. This kind of learning is categorized in philosophy as learn by induction where the learner started with a few examples then generalize it to new situations where he/she has never seen before. Learning by induction or by example is supervised learning. From Fig-1 below, take a guess of what kind of objects that are shown below. Majority of readers here had never seen the objects before, but you must have some rough idea of what the objects are & what use are they aim for. See the answer at the end of this article, if your guess is correct.

Figure 1: Mystery Objects
Ancient learners learnt by self-discovery when they linked high tide to gravitation effects of the interaction between the sun, earth & the moon. No experts taught them this scientific fact, yet they simply observed & figured out this connection on their own. Philosophically this type of learning is deduction by its nature which is unsupervised, i.e., no one taught those ancient leaners about this scientific fact.
Machines
Computer scientists and software developers, in general, apply the notion of learning to machines, as well. Machines can learn by being taught (a computer programmer, or an expert in a specific domain such as a lawyer, doctor, and so forth) or learn from self-discovery by observing data (such as data from a marketing database, patients’ management database, movie or TV text commentaries on Facebook, and so on) and being able to discover and extract predictive hidden information. They also are able to acquire new knowledge by predicting the outcome of new cases that are encountered during the process of learning. Examples of learning in machines is Artificial Neural Network (ANN) method. It is a type of mathematical algorithm that was first developed by Warren McCulloch and Walter Pitts in1943, based on neuron interconnection networks in the human brain & it has been implemented in different types of software applications today. The ANN software systems, is fed in labeled data for classifications, such as lung cancer patient records in the last five years from a specific hospital. There is no prior general knowledge at all about the patient records’ data.
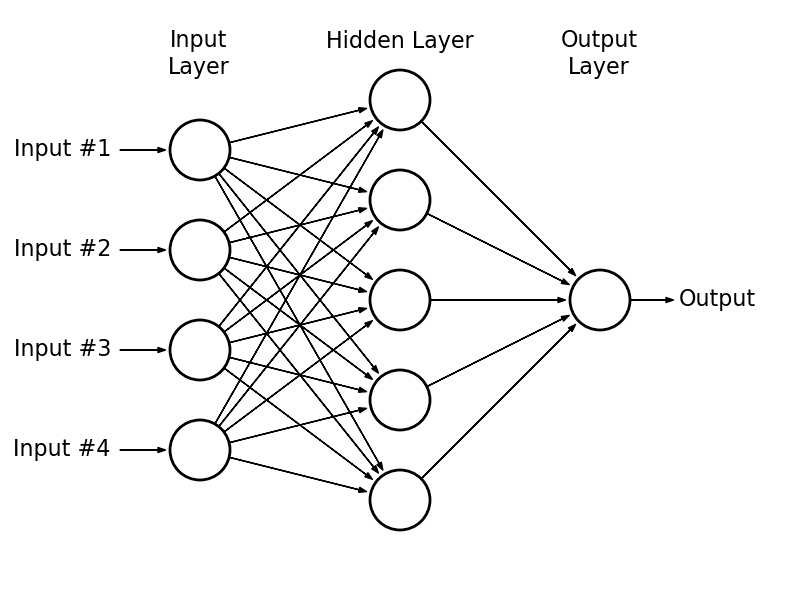
Figure 2: Three – Layer Neural Network with 4 inputs (attributes/features) and 1 output. Photo Credit:
http://www.astroml.org/book_figures/appendix/fig_neural_network.html
The task of ANN as in an inductive learning framework is to correctly classify new instances of the data (such as newly admitted patients whose medical conditions have not been accurately determined from an initial diagnosis) according to patterns it has discovered from the training data, during the learning stage whether the patient shows signs of early cancer development or not based on the MRI image scan of the patient which used as input to ANN system. So, ANN is a paradigm of machine learning that learns by being taught since it has been trained on labeled data where cancer patients are already labeled & shown how attributes or features of cancer look like. There are tons of methods in machine learning not just ANN that are available today & new methods are being published in various related academic journals on a continual basis that pushes the boundary of machine based intelligence accuracy up. For machines, the term “learning” usually corresponds to a designed model, such as ANN mentioned above. Through the process of learning, we are improving model prediction accuracy as fast and well as possible. After learning, we expect the best fitting model of input data. Some methods that are not very robust give very good results on training data, but on testing or real data they perform poorly. When this occurs, we are talking about over-fitting. The rate of over-fitting is also very dependent on input data. This mostly happens when we do not have much data compared with the number of attributes, or when the data is noisy. The noise gets into data by subjective data providing, uncertainty, acquisition errors, and so on. If we have too many attributes and not much data, the state space for finding the optimal model is too wide and we can easily lose the right way and finish in local optimum. The problem of over-fitting can be partially eliminated by suitable pre-processing and by using adequate learning methods as well as providing good input data. See, the end for your answer to guessing the type of objects in Figure-1 above. If you answer incorrectly, then your own learning of similar objects you’ve seen in the past can be said to be over-fitting. However, if you do guess correctly, then your generalization ability of categorizing of such unseen objects to yourself doesn’t suffer over-fitting.
These types of problems happen often in machine learning as well. Certain ML algorithms being deployed today by banks for example, do frequently fail to recognize fraudulent live transactions of a stolen credit card used by a thief on a spending spree & then it should flag and send re-confirmation security questions to the legitimate card holder via email or text (such as who’s your mother’s name, school you went to, etc) to further verify him/her self before the transactions is allowed to go through or the system should simply cancel such suspicious transactions in order to prevent losses, until the legitimate cardholder made contact with the bank him/her self of why her/his card is rejected at retail shops. Such failure is attributed to over-fitting where the bank’s fraudulent detection system was tested well on their own internal data (with various fraudulent case examples) but yet didn’t recognize a live fraudulent transactions from a stolen credit card used by a thief. Understanding intelligence and creating intelligent artefacts, the twin goals of AI, represent two of the final frontiers of modern science. Several of the early pioneers of computer science, such as Alan Turing, Jon Von Neumann, and Claude Shannon from 60 years ago, to just name a few, were captivated by the idea of creating a form of machine intelligence. The questions and issues considered back then are still relevant today, perhaps even more so.
Machine Learning At Parrot Analytics
At Parrot Analytics, the Data-Science team dig very deep into machine learning techniques for use in our product development. Since the types of analytics we do is so wide, we have adopted & explored techniques from various disciplines such as computer science, information retrieval & natural language processing, machine learning, physics, bio-medical engineering & signal processing (since our data is temporal or time-series based), economics, statistics for product development. Such exploratory work allows us to experiment fast in developing automated machine intelligence system for our products. We not only used existing tools already widely available (open source or commercial) but we also get access to the latest algorithms that have just been made available in the academic research literature & scientific journals. This allows our Data Science team to experiment with cutting edge & state of the art algorithms only known to academic researchers as they are relatively new but not yet widely known to the data science community at large. We not only get access to the latest algorithms but we also collect large number of academic papers in various topics related to the domain of analytics & this gives us a wealth of information to explore in our product development because we want to innovate and lead with huge competitive advantage in our mission to help solve the TV measurement problem.
Puzzle’s Answer : The mystery objects from Figure 1 are cups (Kava cups which are popular with Pacific Islanders). Obvious features of a cup or container that we recognize is its concavity-up. If you guess correctly, then you realize that your inductive learning capability generalizes well & there is no over-fitting.
– Sione Palu, Data Scientist

